State of VLA Research at ICLR 2026
October 2025 • by Moritz Reuss

ICLR’s open submission policy gives a rare, real-time view of what the community is actually building. This post distills the state of Vision-Language-Action (VLA) Models research slice of ICLR 2026: what ‘counts’ as a VLA (and why that definition matters), what people are working on in the VLA field (discrete diffusion, embodied reasoning, new tokenizers), how to read benchmark results in VLA research, and the not-so-invisible frontier gap that sim leaderboards hide.
Each autumn, the ICLR publicly releases all anonymous submissions a few weeks after the deadline,
providing a unique real-time snapshot of ongoing research around the world without the typical six-month delay of other top ML conferences.
Given my personal research interests, I wanted to analyze Vision-Language-Action (VLA) Models research and share insights from this year's submissions.
In this blog post, I briefly explain what VLAs are, share my findings about current trends and challenges in VLA research, highlighting some interesting papers submitted to ICLR 2026.
To help researchers and practitioners better understand the current state of VLA research, I've also included a practical guide on how to interpret benchmark results in VLA papers.
Finally, there is a discussion about the hidden gap between frontier labs and academic research labs in the VLA field—a gap that isn't visible from reading papers alone.
Below is a summary of general research trends with highlighted papers for each category that I found interesting from this year's submissions.
Please note that this represents only my personal selection and opinion of papers and research, and I may have missed other excellent work.
If you know of noteworthy papers that I missed, please let me know.
Table of Contents
What is a Vision-Language-Action Model?
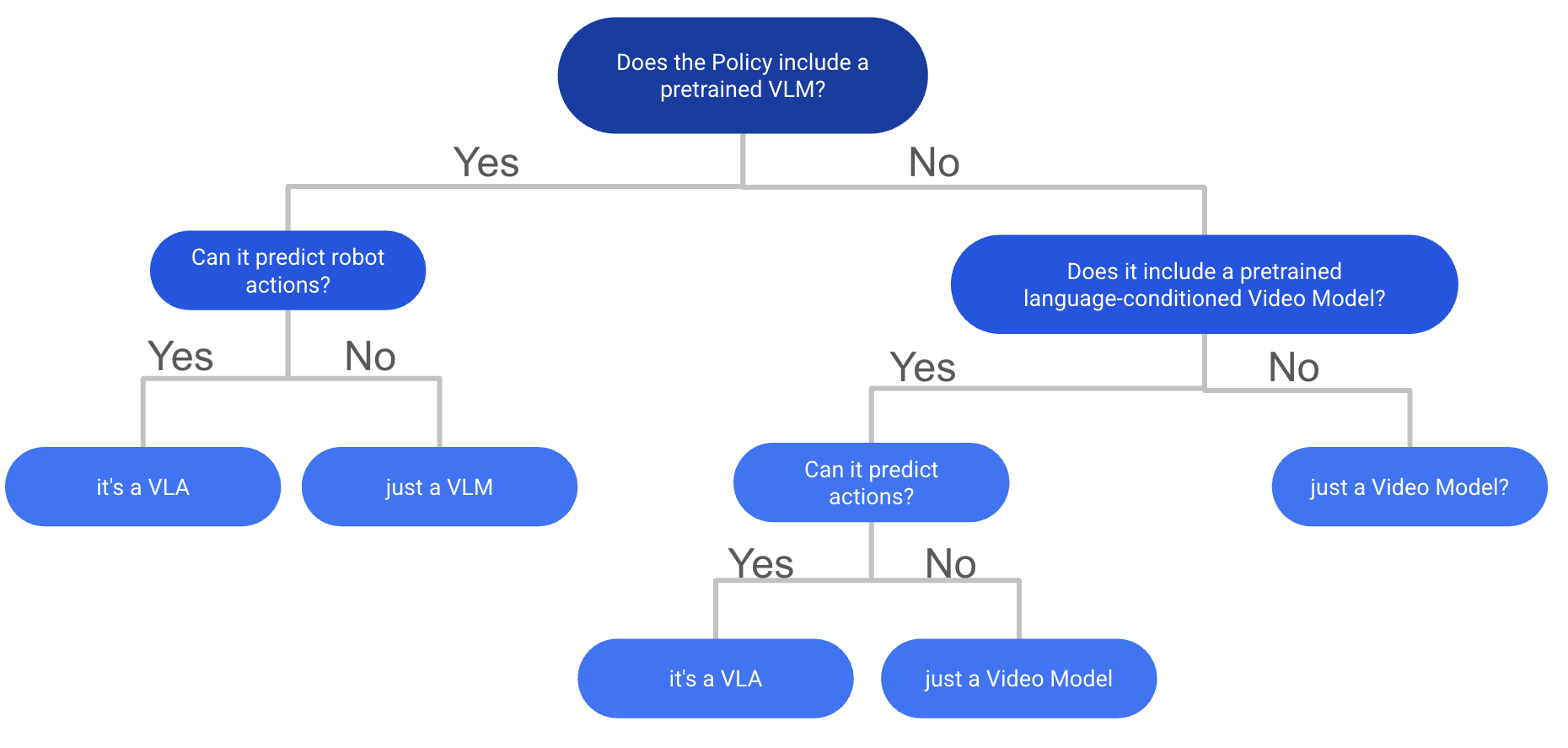
The definition of VLAs is surprisingly contentious, with no clear consensus in the community. A recent survey paper defines it broadly: "A Vision-Language-Action (VLA) model is a system that takes visual observations and natural language instructions as required inputs and may incorporate additional sensory modalities. It produces robot actions by directly generating control commands."
While this is a valid definition, in my personal opinion it misses what I consider the crucial distinguishing feature compared to other multimodal policies: internet-scale pretraining on some type of vision-language data.
My personal definition: A VLA is a model that uses a pretrained backbone, which was trained on large-scale vision-language data and is subsequently trained with generating control commands. This control commands can be robot joints, end-effector poses, steering angle for a car, latent actions or mouse and keyboard commands for a virtual agent. This definition also includes Video-Action Policies that use pretrained video-generation models as their backbone. Without internet-scale pretraining, I refer to these as multimodal policies rather than VLAs. Where it becomes a bit fuzzy is when a model uses a pretrained text encoder like CLIP-text or T5 and a separately pretrained vision encoder like DINOv2 or SigLIP-Vision. In my personal opinion, I like to group these as multimodal policies and not VLAs since they are lacking the joint vision-language pretraining. For reference I also included a flowchart (Figure 1) to help you determine if your model is a VLA or not based on my definition.
This distinction matters because internet-scale pretraining is what theoretically gives VLAs their moat: stronger language-instruction following and better generalization across tasks and environments. That's the promise, at least. The reality? Most current VLAs still struggle with zero-shot generalization and complex tasks, making them better described as "less dumb multi-modal policies" rather than truly general robot brains. But the potential is there and it has many exciting open problems for researchers to tackle.
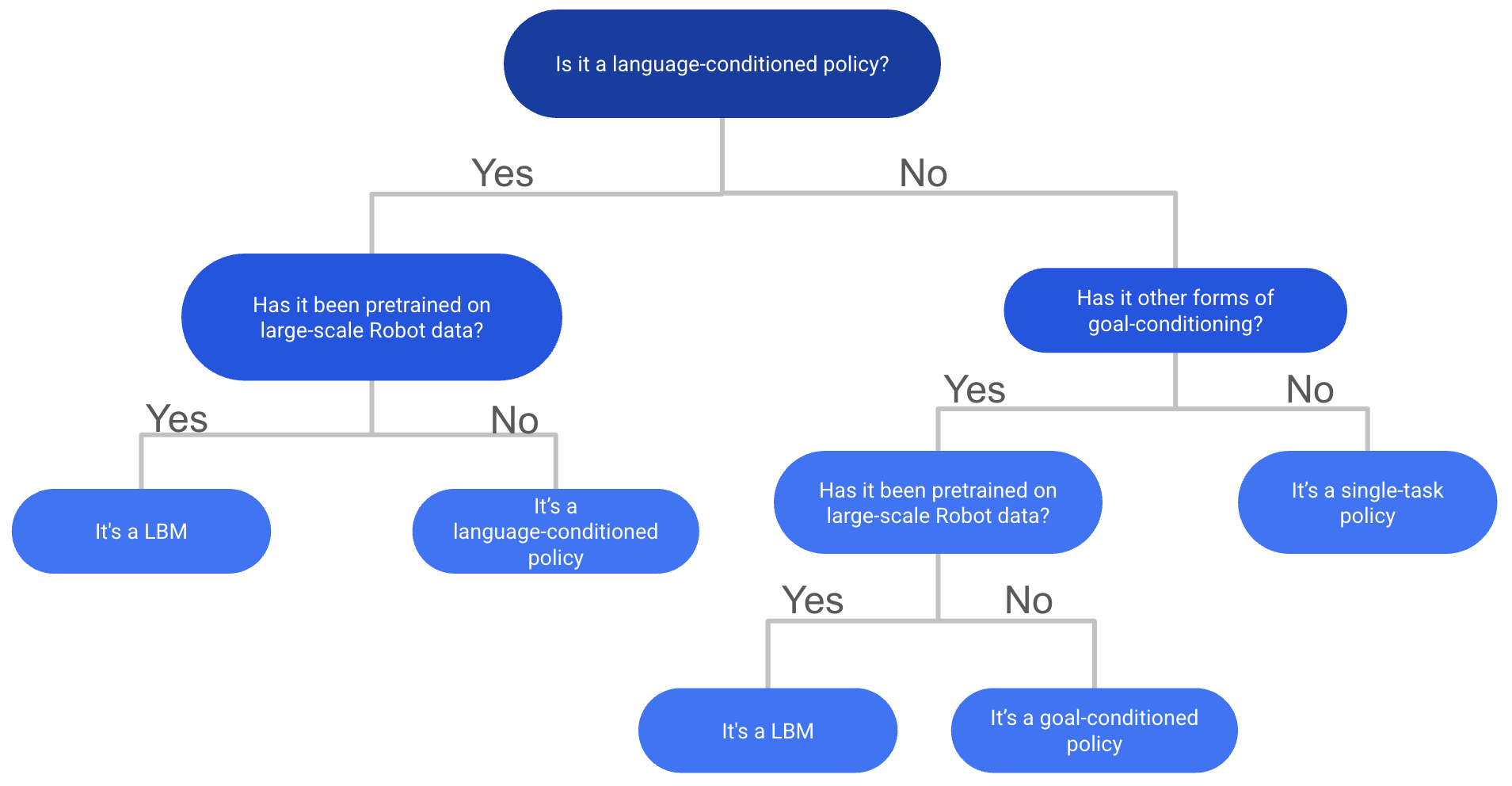
Related and complementary: Large Behavior Models (LBMs), a term from Toyota Research Institute (TRI) defined in their recent paper, represent another category. LBMs are robot policies trained on large-scale multitask robotic demonstration data, but they don't require internet-scale vision-language pretraining or a VLM backbone. Think of it this way: all VLAs trained on large-scale robotic data are also LBMs, but not all LBMs are VLAs. Together these two terms cover all types of robot foundation policies. I also included a flowchart (Figure 2) to help you determine if your model is a LBM or not based on my understanding
What's your personal definition of a VLA? Do you agree with my take on internet-scale pretraining as the key differentiator? Let me know your thoughts!
The Explosive Growth of VLA Research
The Vision-Language-Action field has experienced remarkable growth over the past two years. Based on keyword searches on OpenReview, the numbers tell an interesting story based on ICLR submissions openreview keyword search for "Vision-Language-Action":
- ICLR 2024: Only 1 rejected submission with "Vision-Language-Action" keyword
- ICLR 2025: 6 accepted papers and 3 rejected submissions with the same keyword
- ICLR 2026: 164 submissions with the same keyword—an 18x increase in just one year!
This exponential growth trajectory shows that Vision-Language-Action models are rapidly gaining popularity with many new people from other domains like Vision coming into the exciting field of robot learning. Given this trend, I'm both excited and a bit terrified to review the projected 2,100+ VLA submissions at ICLR 2027, though I suspect the growth rate may stabilize as the field matures.
Practitioner's Guide to Understanding Benchmark Results in VLA Research

I want to provide a quick guide for practitioners on how to interpret benchmark results in VLA papers.
So you are reading a new VLA paper and want to understand if the claimed results are actually good or not?
In order to better understand the VLA results, it is important to have some context on the current state of popular VLA benchmarks and what good performance looks like.
Given the current benchmarks, there is no clear statement possible to say which model is the best, as most papers only compare against each other on the usual simulation benchmarks.
90% of papers mentioned in this post all test in either LIBERO, SIMPLER or CALVIN.
LIBERO is basically solved and showing 99% vs 98% is not very helpful and you don't need VLAs and large-scale pretraining to get competitive results.
E.g. all mentioned concurrent discrete diffusion policies below test on LIBERO and all achieve between 95-98% average over the 4 versions (Goal, Spatial, Long, Object).
It's also funny to note that LIBERO was designed as a life-long learning benchmark but 99% of models reporting results on it just train on the full dataset and don't do any continual learning.
Based on these results it is impossible to say which model is better, as they are all very close to the ceiling anyways and you don't need internet scale pretraining to solve these.
Rule of thumb for getting a impression a VLA is decent or near sota levels on these: LIBERO: >95% is expected for Spatial, Goal and Object, 90-95% is required for Long and 90, lower than 90% is only fine for static-camera-only or few-shot stuff.
A properly tuned Diffusion Policy can get you there without VLAs although the most cited DP baselines is showing worse results.
CALVIN is also almost saturated by current sota models like FLOWER.
The benchmark has 3 main version: D (train on setup D and test on setup D), ABC (train on A,B,C and test on D) and ABCD (train on A,B,C, D and test on D).
ABC is the most relevant one, as it tests generalization to unseen setups, ABCD test how well methods benefit from more diverse data and D tests fine-tuning.
For CALVIN higher than 4 score for ABC is standard now and above 4.5 is sota regime.
For the D version 3.75 is standard and above 4 is very good.
For the ABCD version results above 4.5 are relevant.
SIMPLER is hard to interpret across setups; success spans 40–99% on Bridge, making cross-paper comparison noisy.
For the Google Robot version current sota models achieve around 70%-80% success rate.
Somehow, RLBench (the most popular 3d policy benchmark) has gained more popularity in VLA benchmarking, but all VLAs are still far away from 3D SOTA methods like 3DDA.
Most VLA policies try to avoid comparing against all relevant 3D baselines for some reason.
Any real world results are very important and more is better, as sim-only is hard to trust especially with VLA papers that use models with 7B+ parameters and are very good in overfitting successfully on these benchmarks.
ICLR 2026 VLA Research Trends
After scanning most ICLR 2026 submissions with the VLA keyword, I identified the following key trends in VLA research. There is significant overlap between these categories, as many papers combine multiple ideas—for example, discrete diffusion with embodied reasoning, or efficient architectures with new tokenizers. Below, I highlight some notable papers in each category along with brief comments. Please note that this is not an exhaustive list, and I may have missed many excellent works.
1. Discrete Diffusion VLAs
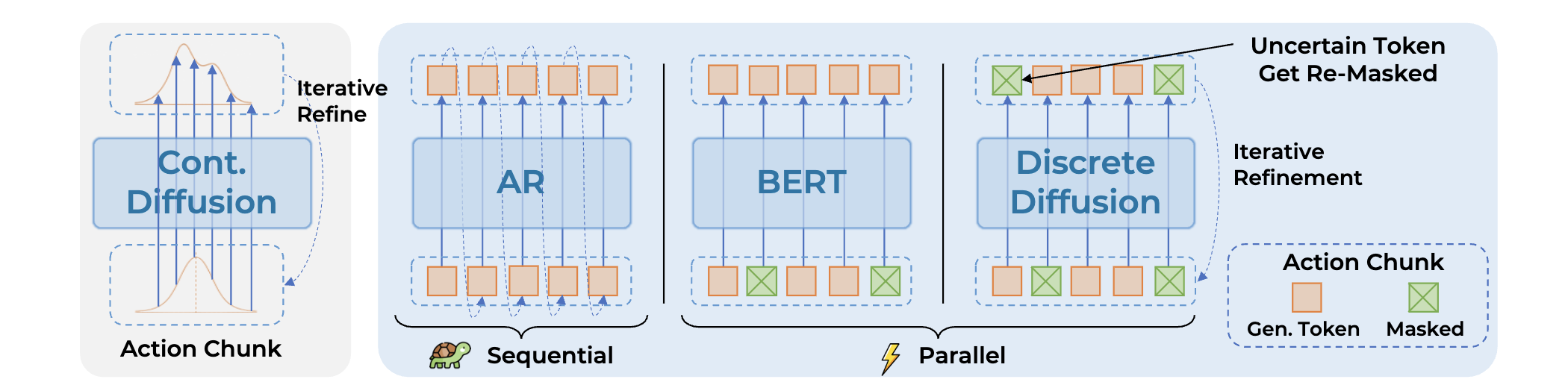
Given the success of discrete diffusion models in other domains like text (e.g. (MDLM) and VLMs (e.g. LLaDA-V), it is no surprise that this trend is also making its way into VLA research. Why discrete diffusion? Compared to autoregressive models, diffusion models can generate sequences in parallel, which is a big advantage for discrete action token generation. Instead of having to run your policy 100 times, you can generate long action sequences in a few forward passes. In addition, you can combine it with ideas from Embodied Chain-of-Thought (see next section) to generate sub-goals and reasoning together with actions in parallel. This tackles some of the biggest limitations of ECoT from prior work, which was extremely slow due to the autoregressive nature of the VLM models. Current attempts for discrete Diffusion either finetune an autoregressive VLM with discrete diffusion because the variety of discrete diffusion VLMs is very limited. Other work uses LLaDA-V as a pretrained backbone with good success. Below are 4 concurrent papers that all propose different discrete diffusion VLAs with promising results on LIBERO and SIMPLER.
Notable papers:
-
DISCRETE DIFFUSION VLA: BRINGING DISCRETE DIFFUSION TO ACTION DECODING IN VISION-LANGUAGE-ACTION POLICIES
TL;DR: Take OpenVLA and apply Discrete Diffusion Action Prediction for fast action chunk-based generation of discrete action tokens. Also proposes adaptive decoding for inference. Strong results on LIBERO + SIMPLER. -
dVLA: DIFFUSION VISION-LANGUAGE-ACTION MODEL WITH MULTIMODAL CHAIN-OF-THOUGHT
TL;DR: Another Discrete Diffusion VLA using Co-Generation for Future Frames and text + actions given the advantage of fast parallel sampling of Discrete Diffusion over AR models. Basically ECoT + Discrete Diffusion done well. Also good results in LIBERO + real world experiments. -
DIVA: DISCRETE DIFFUSION VISION-LANGUAGE-ACTION MODELS FOR PARALLELIZED ACTION GENERATION
TL;DR: Another discrete Diffusion VLA that also focuses on how to substitute tokens during inference for better performance. -
UNIFIED DIFFUSION VLA: VISION-LANGUAGE-ACTION MODEL VIA JOINT DISCRETE DENOISING DIFFUSION PROCESS
TL;DR: Generates future frames and discrete actions together with block-wise causal masking. Results on CALVIN, LIBERO and SIMPLER are good.
2. Reasoning VLAs and Embodied Chain-of-Thought (ECoT)
Reasoning holds strong promise for improving the generalization and performance of VLAs, which still struggle with complex tasks and out-of-distribution scenarios. Inspired by the success of Chain-of-Thought prompting in LLMs, there is growing interest in applying similar ideas to VLAs. The core idea is to bridge action generation with intermediate visual and textual reasoning steps that help the VLA better ground and understand the task and environment. These reasoning traces are also more interpretable and can be used for debugging and understanding a VLA’s behavior.
Since the first ECoT paper (CoRL 2024), interest has grown in combining spatially grounded reasoning with action prediction to improve VLAs. By combining subtasks, bounding-box predictions for task-relevant objects, and 2D motion trajectories, VLMs learn better representations for embodied tasks and show improved performance on generalization benchmarks. Prior analyses of ECoT training indicate that these objectives help bridge the representation gap between VLM static pretraining and robotics tasks. However, a key limitation of prior ECoT work is the autoregressive nature of VLAs and the increased token count, which results in slower training and inference.
Overall, it remains an open question how to best implement grounded reasoning for VLAs. Recent work has explored additional modalities like depth prediction in MolmoAct. A major bottleneck is the limited availability of diverse training data: many ECoT studies still rely on the same BRIDGE and LIBERO labeled datasets. More diverse datasets with more complex tasks and environments are needed to push this direction further; however, labeling large-scale sources like DROID is tough.
Notable papers:
-
ACTIONS AS LANGUAGE: FINE-TUNING VLMS INTO VLAS WITHOUT CATASTROPHIC FORGETTING
TL;DR: Instead of directly fine-tuning VLMs with discrete action tokens to become VLAs, which results in catastrophic forgetting, they relabel robot datasets with subtasks, actions as text and intermediate motion-planning like "move left". This training method is able to bridge the domain gap of VLMs without reducing performance on other VQA benchmarks from pretraining. Finally cheap LORA finetuning is enough to get strong results for action prediction while maintaining VLM reasoning capabilities. -
VISION-LANGUAGE-ACTION INSTRUCTION TUNING: FROM UNDERSTANDING TO MANIPULATION
TL;DR: InstructVLA proposes a two-stage Vision-Language-Action Instruction Tuning pipeline that tries to preserves a pretrained VLM’s multimodal reasoning while adding precise manipulation: (1) pretrain an action expert and latent action interface, then (2) instruction-tune a MoE-adapted VLM to switch between textual reasoning and latent action generation. It puts emphasis on decoupling multimodal reasoning and action generation to avoid catastrophic forgetting with an action expert, and introduces an instructed-based SIMPLER benchmark to test instruction-following VLAs. -
EMBODIED-R1: REINFORCED EMBODIED REASONING FOR GENERAL ROBOTIC MANIPULATION
TL;DR: R1 is a pointing VLM for embodied reasoning: it trains Qwen2.5-VL base with a two-stage Reinforced Fine-Tuning (RFT) curriculum on the new Embodied-Points-200K dataset. It uses an embodiment-agnostic intermediate REG (point to the referred object), RRG (point to a relation-defined place), OFG (point to a functional part, e.g., a handle), VTG (output a sequence of points as a visual trace/trajectory). Strong performance on embodied benchmarks and pointing ones with good generalization to SIMPLER as planner with intermediate waypoints. -
HYBRID TRAINING FOR VISION-LANGUAGE-ACTION MODELS
TL;DR: Decomposes ECoT pretraining in several subtasks of think act and follow, that enable to maintain the performance benefits with fast inference. Similar findings, that Co-Training with ECoT stuff results in better representations for action prediction.
3. New Tokenizers
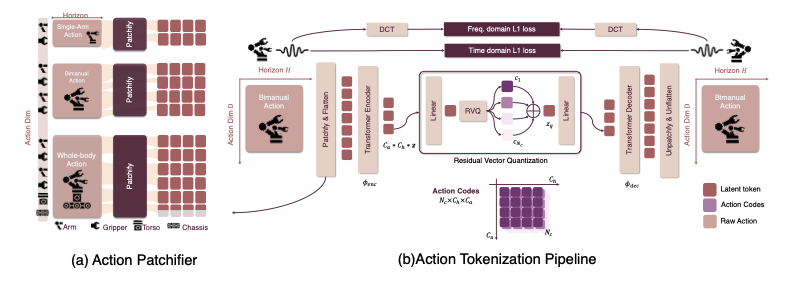
We command robots with high-frequency, continuous control values (e.g., joint angles, gripper state). Vision-Language models, however, operate most effectively on discrete tokens. Naively fine-tuning a VLM to regress continuous actions tends to underperform and often induces catastrophic forgetting, because the new objective misaligns with the model’s pretrained representations.
The core idea of these tokenizers is to convert continuous action sequences into compact discrete tokens that a VLM can predict—retaining accuracy and smoothness while minimizing compute and integration overhead. An ideal action tokenizer is fast, achieves a high compression ratio for long action-chunks, produces smooth long-horizon outputs, and drops into existing VLM architectures without modification.Prior work used discrete binning (e.g., RT-1) and VQ-VAE codebooks, but both struggle with either coarse precision or long-sequence efficiency. FAST introduced action-chunk tokenizers tailored for VLA prediction, demonstrating that discrete tokens can replace more complex diffusion/flow experts for integration. Building on this, newer tokenizers submitted to ICLR combine Residual Vector Quantization (RVQ) (e.g., SoundStream) for higher compression, spline-based parameterizations inspired by BEAST tokenizer for smooth, long trajectories, and DCT-style objectives (as in FAST) to bias toward low-frequency, physically plausible motion. I’m excited to test these tokenizers myself when they release.
Notable papers:
-
FASTER: TOWARD POWERFUL AND EFFICIENT AUTOREGRESSIVE VISION–LANGUAGE–ACTION MODELS WITH LEARNABLE ACTION TOKENIZER AND BLOCK-WISE DECODING
TL;DR: Introduces a novel discrete action tokenizer called FASTer, that combines Residual Vector Quantification (RVQ) with a frequency L1 loss using DCT and time domain L1 loss for improved performance. Also patchifies action tokens along the temporal axis and grouped action dimension axis (e.g. base motion, arm joints). It has a higher compression ratio than FAST and results on SIMPLER and LIBERO are strong. -
OMNISAT: COMPACT ACTION TOKEN, FASTER AUTOREGRESSION FOR VISION-LANGUAGE-ACTION MODELS
TL;DR: Another tokenizer for VLAs that uses our BEAST paper idea of B-Splines for compact representation of continuous action chunks. It uses a two stage encoding process: First, aligning the different action chunk lengths of different embodiments into a normalized, fixed-length representation. Next, it uses a B-Spline based encoder to get a compact representation of the normalized action chunk. Finally, a VQ-VAE is used to get discrete tokens. Results on LIBERO and SIMPLER are good and across all benchmarks improves upon both FAST and BEAST.
4. Efficient VLAs
As someone working on this topic myself, I understand the pain of trying to train and run larger VLAs on limited compute setups. Thus, efficient VLAs are always relevant. Especially since this gives labs with limited compute access the chance to work on VLAs too. There are several interesting papers this year that try to tackle this problem with different approaches. Generally, one can divide them into two categories: try to make training and models more efficient by making smaller VLAs or better tokenizers etc. Otherwise, a lot of papers focus on making inference more efficient by using better quantization, distillation or similar ideas.
Notable papers:
-
HYPERVLA: EFFICIENT INFERENCE IN VISION- LANGUAGE-ACTION MODELS VIA HYPERNETWORKS
TL;DR: HyperVLA uses hypernetworks to generate small task-specific policies conditioned on language instructions and initial images, dramatically reducing inference cost while maintaining performance by only activating the compact generated policy during execution instead of a big VLA model. -
AUTOQVLA: NOT ALL CHANNELS ARE EQUAL IN VISION-LANGUAGE-ACTION MODEL’S QUANTIZATION
TL;DR: Analysis quantization of OpenVLA and proposes improved quantization method for maintaining performance with only 30% of the original VRAM requirements.
5. RL for VLAs
Finetuning VLAs to go from 70-80% success rate in the real world to 99% is still an open problem. There is a lot of hope for RL Finetuning to close this gap. While a lot of attempts have been made before, no method has established itself as the go-to method yet. This year there are several interesting papers that try to tackle this problem with different approaches.
Notable papers:
-
SELF-IMPROVING VISION-LANGUAGE-ACTION MODELS WITH DATA GENERATION VIA RESIDUAL RL
TL;DR: Residual RL method that collects more data with frozen VLA and small residual policy. The residual interventions are used to get more high quality data with recovery behavior. Finally the VLA is finetuned using SFT. Results on LIBERO achieve 99%. -
PROGRESSIVE STAGE-AWARE REINFORCEMENT FOR FINE-TUNING VISION-LANGUAGE-ACTION MODELS
TL;DR: The method breaks robot tasks into semantic stages (Reach→Grasp→Transport→Place) and assigns rewards to each stage instead of the whole trajectory. It uses STA-TPO for offline preference learning and STA-PPO for online reinforcement learning, both operating at the stage level. Results on Bridge SIMPLER of 98%.
6. VLA + Video Prediction
Video generation models learn rich representations of temporal dynamics and physical interactions, which may provide useful priors for robotic control. Following strong results from the GR-1 paper at ICLR 2024, which demonstrated the potential of video-based policies, interest in this subfield has grown. These policies generally fall into two categories: (1) starting with a VLM that has optionally been pretrained on image/video generation, then continuing training with future frame and action prediction; or (2) starting from a Video Foundation Model and modifying it to also generate actions.
Since most state-of-the-art video foundation models are diffusion/flow-based, these policies typically struggle with slow inference speed. Overall, results demonstrate that video generation—and the physics understanding and language grounding it requires—provides a valuable prior for robot learning. Compared to VLAs initialized from VLMs, this subfield is far less popular, and I hope to see more research in this direction. What holds back progress is the high computational requirements for finetuning state-of-the-art video models like Wan, which exceed even those of VLM-based VLA finetuning.
Notable papers:
-
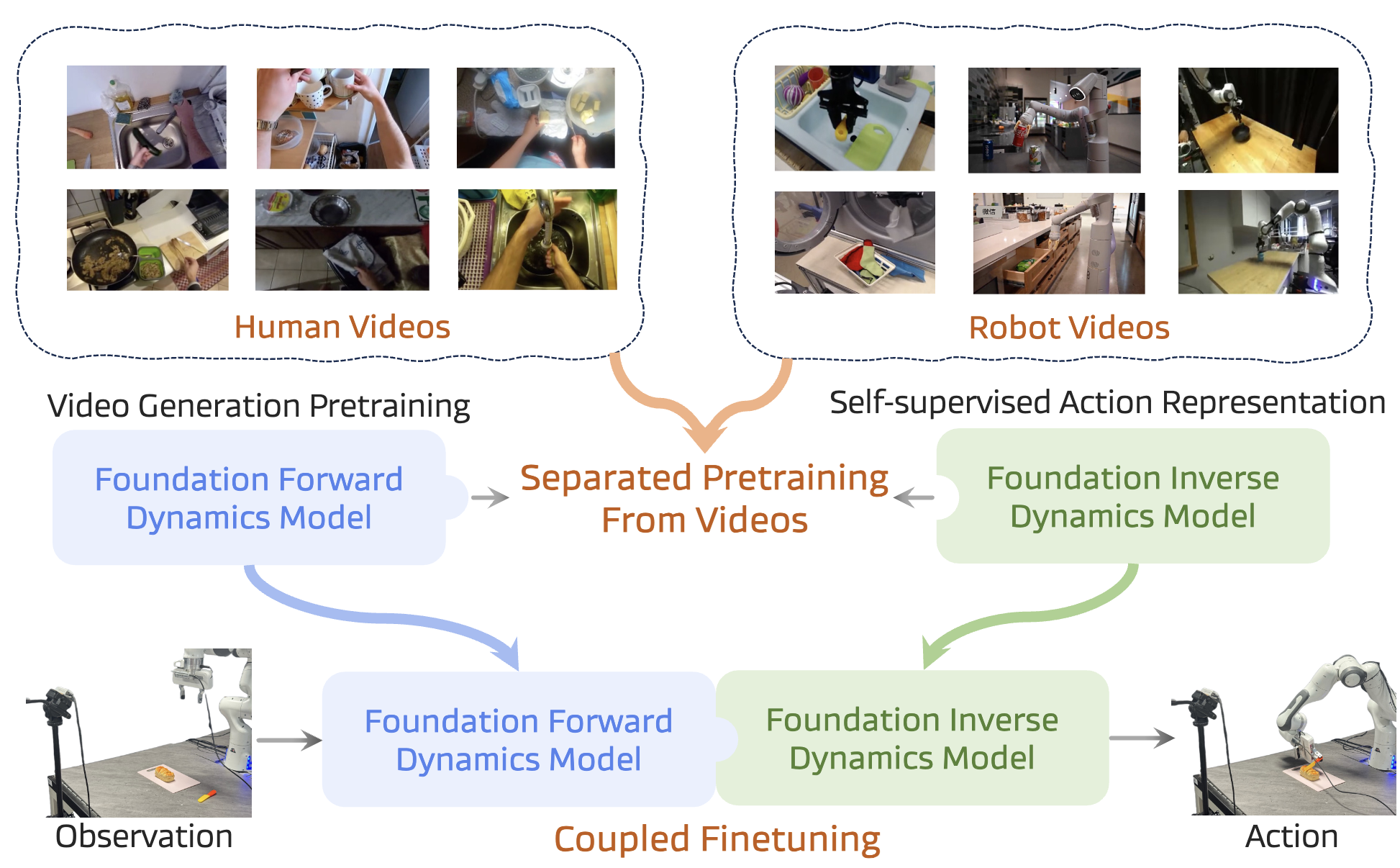
DISENTANGLED ROBOT LEARNING VIA SEPARATE FORWARD AND INVERSE DYNAMICS PRETRAINING
TL;DR: Introduces a novel approach to robot learning by pretraining separate forward and inverse dynamics models pretraining. In the second stage they are combined again for a coupled finetuning of the policy. Results on CALVIN are good on SIMPLER decent. -
UNIFIED VISION–LANGUAGE–ACTION MODEL
TL;DR: Models vision, language, and actions as a single interleaved stream of discrete tokens (VQ image tokens + FAST/DCT action tokens) and trains one autoregressive 8.5B VLA. UniVLA has two training stages for converting the VLM into a VLA: First post-train VLM with text and images to predict future frames, next is the fine-tuning stage with vision and action token prediction. Main emphasis on the post-training stage to better align VLM representations with robot tasks. Results on CALVIN, LIBERO, and SimplerEnv-Bridge are strong. -
COSMOS POLICY: FINE-TUNING VIDEO MODELS FOR VISUOMOTOR CONTROL AND PLANNING
TL;DR: Finetunes the Cosmos Video Foundation Model from NVIDIA for action prediction. Core idea is to inject additional modalities like future action chunks or value function estimations into latent token sequence. Results on LIBERO are good and they also have real world comparisons against Pi0.5.
7. Evaluation and Benchmarking of VLAs

As mentioned above, the current state of VLA benchmarks is quite saturated and it is hard to judge which model is actually better given the limited number of benchmarks and the fact that most papers only compare against a few other baselines. Luckily, there are several submission that try to bridge this gap by introducing new benchmarks for VLAs. Other ideas include real2sim world models to test policies in generative environments. While I don't think these ideas are on a good enough level yet to be used as real alternatives yet, it's a very exciting research area that I hope to see more progress in the future.
Notable papers:
-
ROBOTARENA ∞: UNLIMITED ROBOT BENCHMARKING VIA REAL-TO-SIM TRANSLATION
TL;DR: Introduces a new benchmarking framework for real2sim setup that has similar rating system to the RoboArena. It provides automatic environment construction and evaluation using physics engine, real-2-sim translation and human feedback. They use real2sim translation pipeline with a bunch of foundation models and differentiable rendering and VLM-based task progression scores. Seems very interesting on first glance and I am excited to try it out myself. -
ROBOCASA365: A LARGE-SCALE SIMULATION FRAMEWORK FOR TRAINING AND BENCHMARKING GENERALIST ROBOTS
TL;DR: Extends the initial RoboCasa sim and benchmark setup with a very diverse setup of 365 tasks across 2k+ kitchen scenes and more than 2k hours of teleop data. The task setups look great and the data scale is also promising I just wish they tested more baseline policies than just 3. -
WORLDGYM: WORLD MODEL AS AN ENVIRONMENT FOR POLICY EVALUATION
TL;DR: WorldGym proposes using an action-conditioned video generation model (world model) as an environment for evaluating robot policies, where policies are rolled out in the generated world and evaluated by a vision-language model that provides rewards.
8. Cross-Action-Space Learning
Most VLAs still avoid pretraining on diverse action spaces, given the difficulties of getting any positive transfer results. Thus, it is a very exciting research area for current VLAs to improve. In addition, there is a growing interesting in using human egocentric videos with action labels for pretraining VLAs. Datasets like EgoDex released earlier this year now enable more research in this direction. Several interesting papers are submitted this year that try to tackle this problem with different approaches. They either focus on architecture details of VLAs to better handle heterogeneous action spaces or use additional abstractions like motion in image-space to get better transfer. It's noteworthy that the recent Gemini Robotics 1.5 release from DeepMind indicates that a unreleased technique called motion transfer works for them to get positive zero-shot task transfer inbetween action spaces. So maybe this is just a data and model scale question. Nevertheless, more research is needed to better understand and tackle these issues.
Notable papers:
-
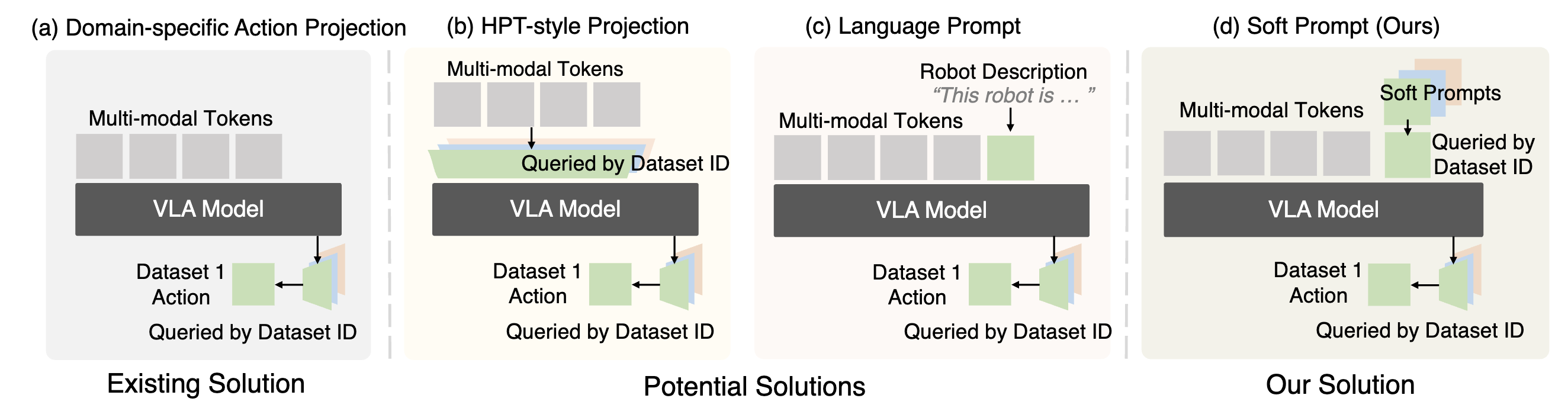
X-VLA: SOFT-PROMPTED TRANSFORMER AS SCALABLE CROSS-EMBODIMENT VISION-LANGUAGE-ACTION MODEL
TL;DR: Tackles cross-action-space learning using soft-prompting tokens for different datasets. These soft-prompt tokens are learnable readout-tokens for the VLA. Results on LIBERO, CALVIN and SIMPLER RoboTwin and VLABench are all very good. Also very insightful scaling analysis. -
XR-1: TOWARDS VERSATILE VISION-LANGUAGE-ACTION MODELS VIA LEARNING UNIFIED VISION-MOTION REPRESENTATIONS
TL;DR:XR-1 introduces Unified Vision-Motion Codes (UVMC), a discrete latent representation that jointly encodes both visual dynamics and robotic motion using a dual-branch VQ-VAE with a shared codebook. This enables better co-pretraining from human and robot demonstrations. Tested on real world experiments against Groot-N.1.5 and Pi0 with good results. -
HIMOE-VLA: HIERARCHICAL MIXTURE-OF-EXPERTS FOR GENERALIST VISION–LANGUAGE–ACTION POLICIES
TL;DR: Substitutes Pi-Style Action Expert with Hierarchical Mixture-of-Experts Transformer to better adapt to new embodiments. It interleaves standard blocks with two types of MoE Blocks: Action-Space MoEs and Heterogeneity Balancing MoEs to better handle different action spaces. Improves upon Pi0 across a range of experiments.
9. Other Interesting Papers
There are several other interesting papers that don’t fit neatly into the categories above but are worth mentioning. They explore varied aspects of VLA design, from the choice of VLM backbone to adding memory modules into the policy. I’m especially interested in memory: most VLAs encode only the current image and ignore prior timesteps, which is a major limitation for many tasks.
Naively feeding long histories into VLAs often backfires: models overfit to demonstrator-specific trajectories, and during rollouts the agent rarely encounters the same state sequences, leading to large performance drops. By contrast, memory modules that aggregate and compress past context (rather than memorizing it) look promising. Hopefully this makes learned policies more robust to distribution shift while preserving the temporal cues needed for long-horizon control.
Another cool work I wanted to highlight is the challenge of composing multiple policies at test time to improve performance. Diffusion and flow-based VLAs are required for this, since their energy-based formulation allows combining multiple models by summing their scores. This is a promising direction to improve performance without training, and I hope to see more.
Notable papers:
-
HAMLET: SWITCH YOUR VISION-LANGUAGE-ACTION MODEL INTO A HISTORY-AWARE POLICY
TL;DR: Introduces a plug-and-play style memory module with moment tokens to capture temporal stuff from prior timesteps. A proposed memory module aggregates tokens over time to enable history-conditioned prediction. -
COMPOSE YOUR POLICIES! IMPROVING DIFFUSION-BASED OR FLOW-BASED ROBOT POLICIES VIA TEST-TIME DISTRIBUTION-LEVEL COMPOSITION
TL;DR: Introduces a method to compose flow/diffusion-based VLA policies at test time to improve performance over individual policies. The authors use convex optimization and test-time search to compose scores from multiple policies to improve performance. -
VLM4VLA: REVISITING VISION-LANGUAGE-MODELS IN VISION-LANGUAGE-ACTION MODELS
TL;DR: Compares a lot of VLMs as backbone choice for VLAs and finds that downstream performance has no correlation with VLM performance on standard benchmarks. This confirms my own experience in experimenting with various VLM backbones. However, the paper is still limited to benchmark setups only and does not test real robot results.
The Hidden Gap Between Frontier and Research VLAs
On paper (pun intended:)), the gap seems small: on simulation setups (LIBERO, CALVIN) open-source VLAs surpass popular frontier baselines like Pi0.5.
In practice, there is still a bigger gap that only shows up precisely where current papers rarely evaluate: zero-shot, open-world behavior after pretraining.
Two weeks ago at CoRL, the Gemini-Robotics VLA demo attempted a wide range of novel tasks with arbitrary objects and paraphrased language.
My own VLA FLOWER is state-of-the-art on all CALVIN benchmarks, but nowhere close to that level of zero-shot robustness.
Simulation benchmarks hide this delta and current simulation setups don't optimize for this objective.
This gap is not unique to VLAs, the same is true for LLMs and VLMs.
For VLAs, fully open-weight models (that share training recipe, data, code and weights) still lag significantly behind closed-weight models like Gemini-Robotics and Pi0.5 on zero-shot tasks.
(although there seem to be some promising signs that this gap is closing with EO-1 but I haven't tried them myself yet).
This is not to say that open-weight VLAs are useless.
They are very useful for research and have strong performance in a lot of scenarios.
But I wanted to highlight this gap, as I believe it is a significant issue for our community that needs to be addressed in the future.
Why the gap exists (based on what’s visible from papers, discussion with peers and personal experience):
- Benchmark progress saturation masks real progress. When scores cluster near the ceiling, “+0.5%” is not evidence of real improvements.
- High quality Data Gap The current available open-source data is limited in diversity and scale, which limits the training of more general models.
- Understanding of High Quality DataIt's not only the data scale, it's also about the missing knowledge gap of understanding high quality demonstration data.
- Evaluation scope is narrow. Most papers report sim-only or small, locally finetuned setups. Free-form zero-shot language following and unseen objects/rooms are very rare. However, it's important to highlight that proper large-scale evals are only doable by companies.
- Operational constraints. Research groups lack the manpower/time to run large, diverse real-world trials necessary for rapid iteration. Frontier labs operate at a different scale of manpower, funding, and robot fleet size. Thus, many PhDs, including myself, iterate on simulation benchmarks to test and try out their ideas.
- Missing Peer Review Incentives. Reviewers at most major conferences expect head-to-head comparison against open-weight but closed-source trained VLAs on standard sims and strong local finetuning numbers. These benchmarks are good for paper acceptance, but weakly correlated with open-world performance.
Counterarguments against this thesis:
- Research Findings are not equal to performance gains. Many great papers I discussed here have general interesting findings useful for the community and research. Zero-shot Performance is only one aspect of VLA Performance.
What would help to bridge this gap without blowing the compute and human manpower budget:
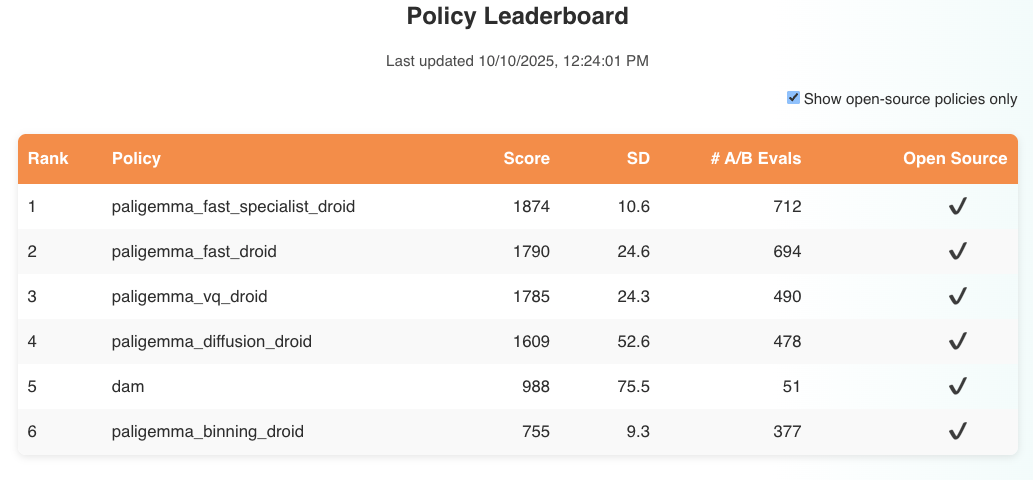
- Usage of public zero-shot fair benchmarks. Track progress on setups like RoboArena that test post-pretraining generalization by independent operators. Today, non-Pi models are scarcely represented and far behind. However, the training code for the higher ranked policies are all fully open-sourced by PI in this codebase to facilitate further research. Another new interesting attempt to tackle this is ManipulationNet. I hope the community is able to adopt some of these for better evaluation.
- Better Pretraining Recipes.” I've seen only very few papers like X-VLA that properly ablate all their pretraining design decisions to understand the impact of these for performance. We need more papers like this that share full pretraining recipes and also discuss failed ideas that did not work during pretraining.
I want to clearly highlight, that I don't think simulation or local finetuning are useless for research in contrast they are very important for many parts of robot learning. Only that they are a poor proxy for the thing for the main argument of VLA: robust zero-shot behavior in messy, new environments.
Summary and Outlook
Overall, I am very positive about the current state of VLA research and the progress being made in this field. The trends above show strong interest and contributions across VLA models—from architecture design to training strategies and evaluation methods. However, there are also a few disappointing aspects aside from the zero-shot performance gap of the current state of VLA research that are worth highlighting.
Two Underrepresented Problems in Current VLA Research:
- Data quality: Despite being critical for VLA performance, surprisingly few ICLR 2026 submissions focused on data collection and curation. It's an open secret that OXE is mostly low-quality data, yet we still lack good methods to quantify data quality in imitation learning. Data-centric research is hard, but understanding how to curate high-quality datasets remains one of the most crucial unsolved problems in VLA research.
- In-context learning: Given the success of in-context learning for LLMs and VLMs, I expected more VLA work in this direction but found almost none. Language alone provides limited context for complex physical tasks—in-context learning could be key to enabling better prompting and zero-shot task generalization for VLAs. There have been some good attempts, but it's still unclear how to best implement this for VLAs in a way that captures the rich contextual information needed to solve complex manipulation tasks.
Despite these gaps, I remain optimistic that the field will continue to grow and evolve rapidly. The explosive growth in submissions and the convergence on promising directions like discrete diffusion and embodied reasoning suggest that VLA research is maturing quickly. As we address these fundamental challenges around data quality and contextual learning, we'll move closer to VLAs that can truly generalize in the messy, unstructured environments where robots need to operate.
Cite this post
If you’d like to cite this article, use the BibTeX below:
@misc{reuss2025state-vla-iclr26,
title = {State of VLA Research at ICLR 2026},
author = {Reuss, Moritz},
year = {2025},
month = {October},
howpublished = {\url{https://mbreuss.github.io/blog_post_iclr_26_vla.html}},
note = {Blog post},
}