|
I am a researcher at NVIDIA's Seattle Robotics Lab, based in Zürich, building efficient and versatile robot foundation models for manipulation. I recently completed my PhD with distinction (summa cum laude) at KIT's Intuitive Robots Lab, supervised by Rudolf Lioutikov. My goal is to make capable generalist robot foundation models efficient enough to train outside frontier labs and practical enough to run on local hardware. Email / CV / Google Scholar / GitHub / LinkedIn / Perspectives |

|
|
Pretrained to Imagine, Fine-Tuned to Act: The Rise of World-Action Models
A map of the World-Action Model landscape, why the approach has become relevant now, and some personal takes on where it may go next.
State of Vision-Language-Action Research at ICLR 2026
A comprehensive overview of VLA research in October 2025: the main ideas, current trends, open questions, and some personal takes. |
|
A 950M-parameter VLA that reaches strong generalist performance while using about 1% of the pretraining compute of much larger models. A mixture-of-experts diffusion policy that improves multitask robot learning while reducing compute, parameters, and inference cost. A diffusion policy that learns long-horizon behavior from language and image goals in uncurated, reward-free offline data. A goal-conditioned diffusion policy that learns diverse behaviors from offline demonstrations with as few as three denoising steps. |
|
|
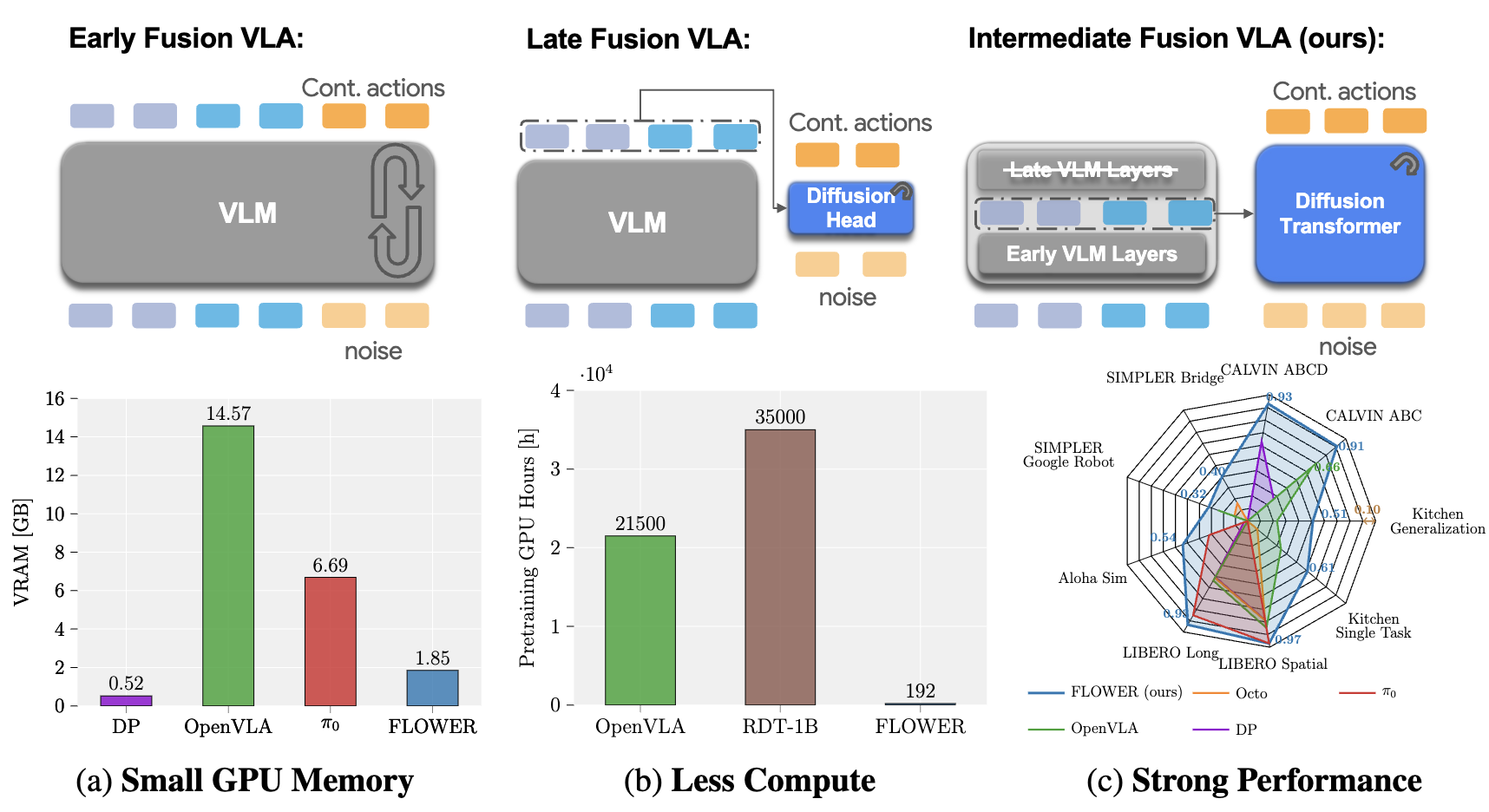
Moritz Reuss, Hongyi Zhou, Marcel Rühle, Ömer Erdinç Yağmurlu, Fabian Otto, Rudolf Lioutikov CoRL, 2025 Project Page / Code / arXiv We systematically analyze VLA design decisions for small and efficient VLAs. Our findings lead us to introduce FLOWER, a 950M-parameter Vision-Language-Action (VLA) policy that achieves state-of-the-art performance across 190 tasks in 10 benchmarks while requiring only ~1% of the pretraining compute of models like OpenVLA. FLOWER introduces intermediate-modality fusion and action-specific Global-AdaLN conditioning to achieve strong performance with improved efficiency. Our approach democratizes VLA development by making high-performance robotic foundation models accessible with commodity hardware, requiring significantly less GPU memory to run. |
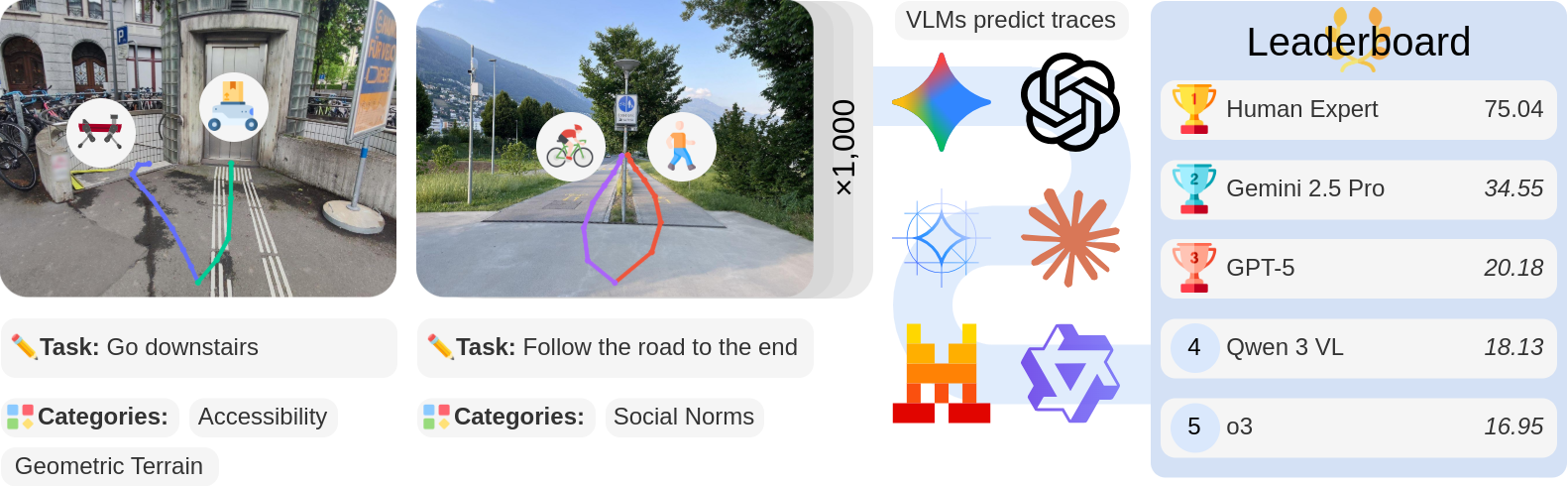
Tim Windecker, Manthan Patel, Moritz Reuss, Richard Schwarzkopf, Cesar Cadena, Rudolf Lioutikov, Marco Hutter, Jonas Frey arXiv Preprint, 2025 Project Page / Code / Dataset / Leaderboard / arXiv We introduce NaviTrace, a comprehensive benchmark for evaluating embodied navigation capabilities of Vision-Language Models. NaviTrace provides a standardized evaluation framework across diverse navigation tasks, enabling systematic assessment of VLMs' spatial reasoning and instruction-following abilities in diverse real-world robotic navigation scenarios. |
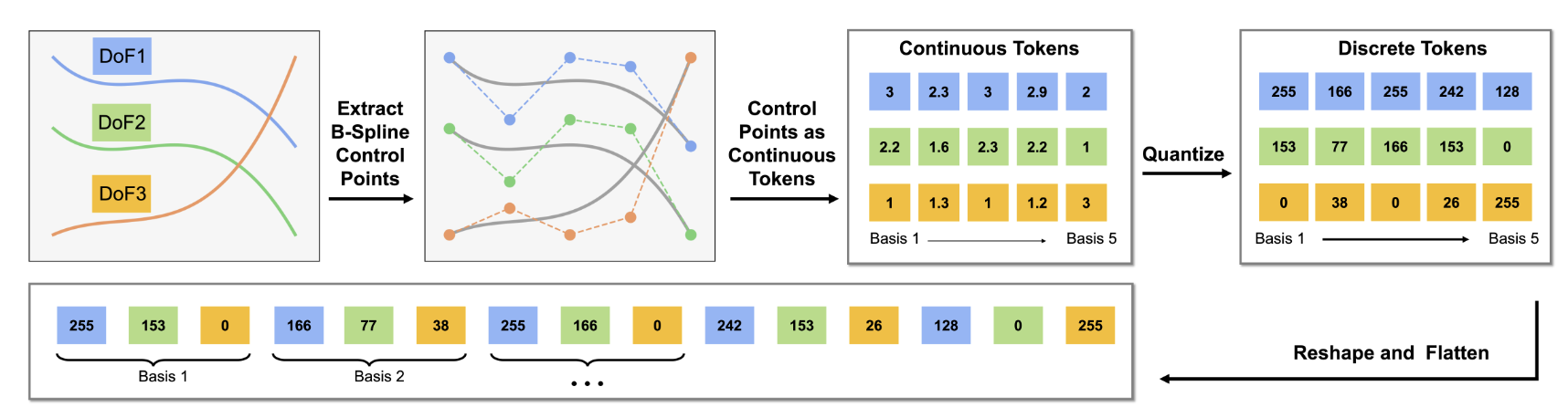
Hongyi Zhou, Weiran Liao, Xi Huang, Yucheng Tang, Fabian Otto, Xiaogang Jia, Xinkai Jiang, Simon Hilber, Ge Li, Qian Wang, Ömer Erdinç Yağmurlu, Nils Blank, Moritz Reuss, Rudolf Lioutikov NeurIPS, 2025 Project Page / Code / arXiv We introduce BEAST, a B-spline–based action tokenizer that efficiently represents continuous robot actions for generalist policies while maintaining smooth trajectories essential for robot control. BEAST enables efficient action representation and improved performance in VLA models by leveraging the mathematical properties of B-splines for smooth, continuous control. It flexibly supports continuous tokens and discrete tokenization. Experiments across various benchmarks verify good compression with strong performance and smooth behavior without additional temporal aggregation. |
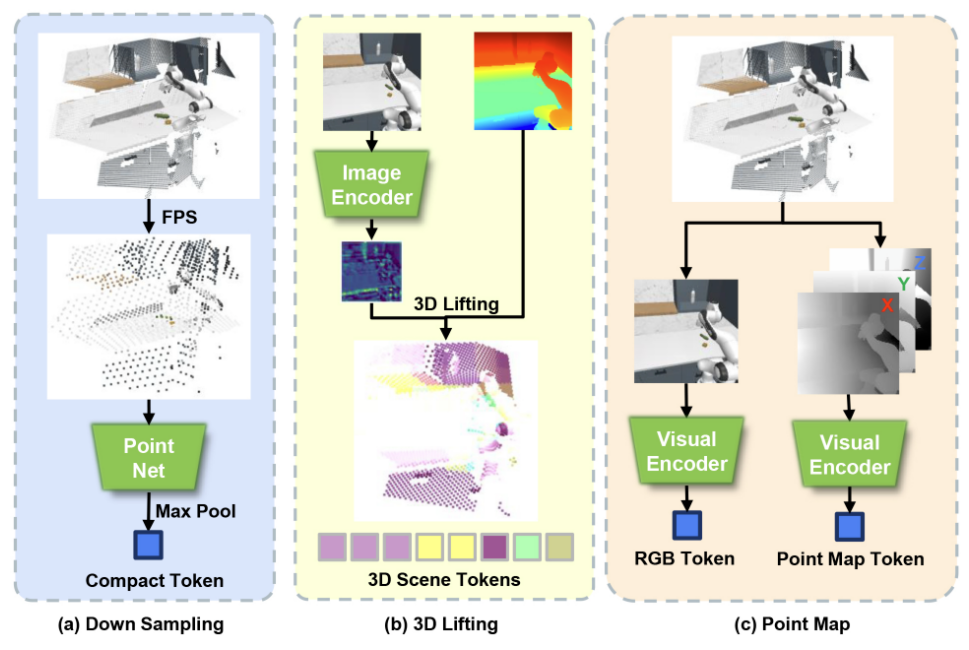
Xiaogang Jia, Qian Wang, Anrui Wang, Han A. Wang, Balázs Gyenes, Emiliyan Gospodinov, Xinkai Jiang, Ge Li, Hongyi Zhou, Weiran Liao, Xi Huang, Maximilian Beck, Moritz Reuss, Rudolf Lioutikov, Gerhard Neumann NeurIPS, 2025 Project Page / Paper We present PointMapPolicy, a multi-modal imitation learning method that conditions diffusion policies on structured grids of points without downsampling. Our approach fuses point maps with RGB using an xLSTM backbone, enabling direct application of computer vision techniques to 3D data while preserving fine-grained geometric details. On RoboCasa and CALVIN, plus real-robot evaluations, we achieve state-of-the-art performance across diverse manipulation tasks. |
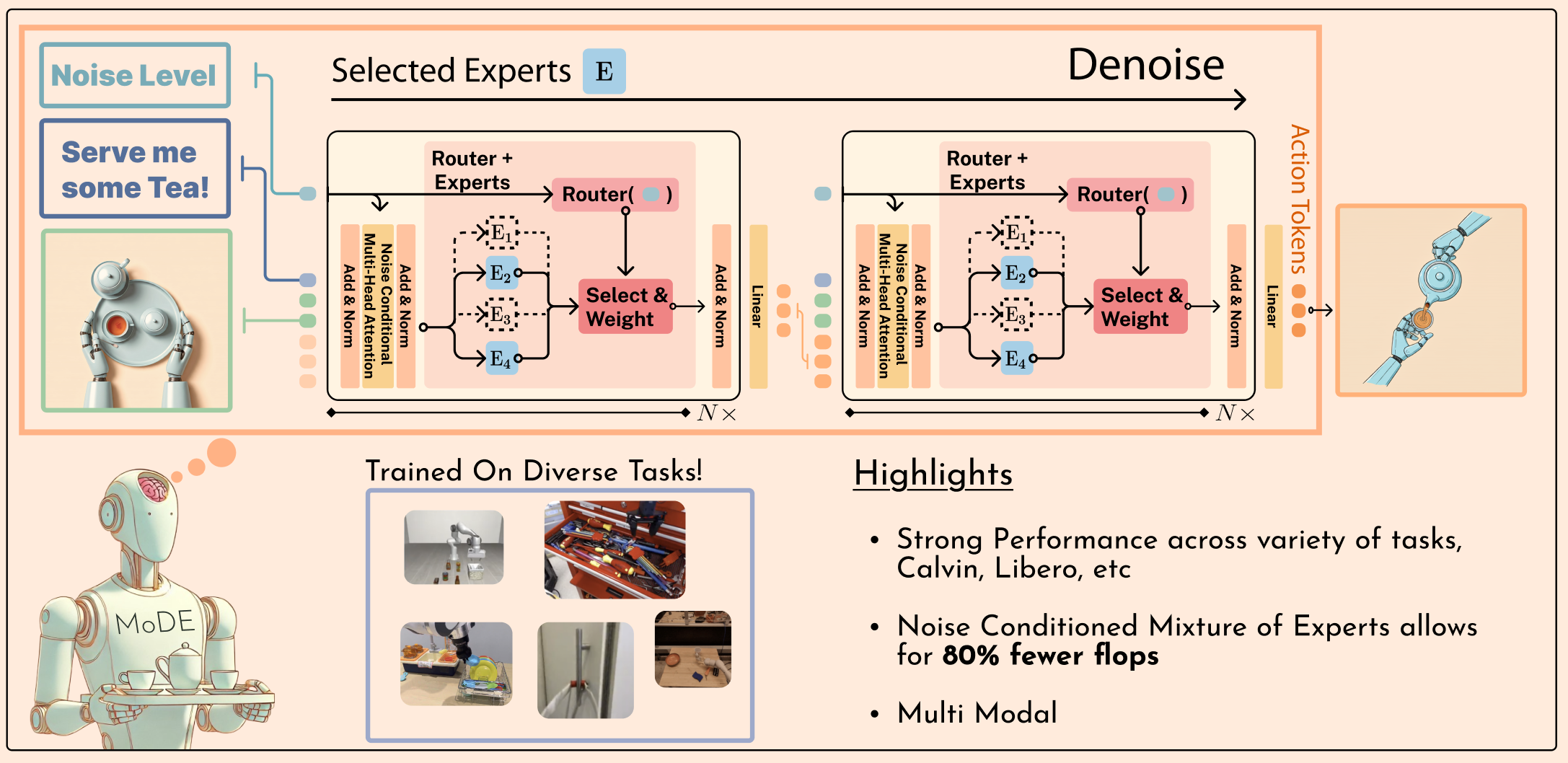
Moritz Reuss*, Jyothish Pari*, Pulkit Agrawal, Rudolf Lioutikov ICLR, 2025 Project Page / Code / arXiv We propose Mixture-of-Denoising Experts (MoDE), a generalist policy for guided behavior generation that outperforms dense transformer-based diffusion policies in accuracy, parameter count, and efficiency. Our routing strategy conditions expert selection on the current noise level of the diffusion process. On four imitation learning benchmarks (including CALVIN and LIBERO), MoDE consistently exceeds dense transformer baselines. We pretrain MoDE on a subset of OXE for just 3 days on 6 GPUs and surpass OpenVLA and Octo on SIMPLER. MoDE achieves higher average performance with ~90% fewer FLOPs, ~20% faster inference, and ~40% fewer parameters compared to dense transformer diffusion policies. |
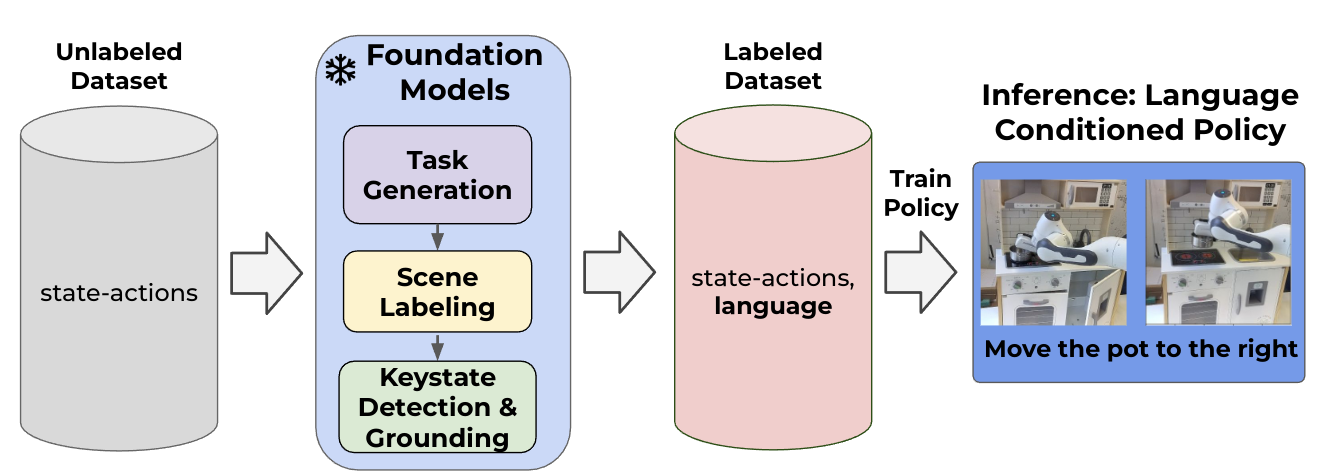
Nils Blank, Moritz Reuss, Marcel Rühle, Ömer Erdinç Yağmurlu, Fabian Wenzel, Oier Mees, Rudolf Lioutikov Conference on Robot Learning (CoRL), 2024 — Oral @ 2nd Workshop on Mobile Manipulation and Embodied Intelligence, ICRA 2024 Paper We introduce a method to automatically label uncurated, long-horizon robot teleoperation data at scale in a zero-shot manner without human intervention. We combine pre-trained vision-language foundation models to detect objects, propose tasks, segment tasks in large unlabeled interaction datasets, and train language-conditioned policies on the relabeled data. Initial experiments show that our method enables policies that match those trained with oracle human annotations. |

Moritz Reuss, Ömer Erdinç Yağmurlu, Fabian Wenzel, Rudolf Lioutikov Robotics: Science and Systems (RSS), 2024 — Oral @ Workshop on Language and Robot Learning (LangRob), CoRL 2023 Project Page / Code / arXiv We present a diffusion policy for learning from uncurated, reward-free offline data with sparse language labels. Multimodal Diffusion Transformer (MDT) learns complex, long-horizon behaviors and sets a new state of the art on CALVIN. MDT leverages pre-trained vision and language foundation models and aligns multimodal goal specifications in the transformer encoder’s latent space, using two self-supervised auxiliary objectives to better follow goals specified in language and images. |

Xiaogang Jia, Denis Blessing, Xinkai Jiang, Moritz Reuss, Atalay Donat, Rudolf Lioutikov, Gerhard Neumann ICLR, 2024 OpenReview D3IL introduces simulation benchmark environments and datasets tailored for imitation learning, designed to evaluate a model’s ability to learn and replicate diverse, multimodal human behaviors. Environments encompass multiple sub-tasks and object manipulations, providing rich diversity often lacking in other datasets. We also propose practical metrics to quantify behavioral diversity and benchmark state-of-the-art methods. |

Moritz Reuss, Maximilian Li, Xiaogang Jia, Rudolf Lioutikov Best Paper Award @ Workshop on Learning from Diverse, Offline Data (L-DOD), ICRA 2023; RSS, 2023 Project Page / Code / arXiv We present BESO, a policy representation for goal-conditioned imitation learning using score-based diffusion models. BESO effectively learns goal-directed, multimodal behavior from uncurated, reward-free offline data and achieves state of the art with as few as three denoising steps. |
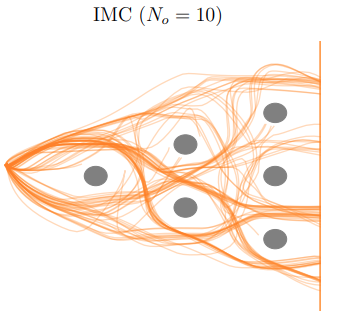
Denis Blessing, Onur Celik, Xiaogang Jia, Moritz Reuss, Maximilian Xiling, Rudolf Lioutikov, Gerhard Neumann NeurIPS, 2023 arXiv We introduce the Information Maximizing Curriculum to address mode-averaging in imitation learning by enabling specialization on representable data. A mixture-of-experts policy focuses on different data subsets, with a maximum-entropy objective for full dataset coverage. |

Moritz Reuss, Niels van Duijkeren, Robert Krug, Philipp Becker, Vaisakh Shaj, Gerhard Neumann Robotics: Science and Systems (RSS), 2022 arXiv We present a hybrid model combining a differentiable rigid-body model with a recurrent LSTM to accurately model the inverse dynamics of a robot manipulator. A differentiable formulation of barycentric parameters enables end-to-end training jointly with the residual network while preserving physical consistency. On a Franka Emika Panda, the model enables precise and compliant motion tracking. |
|
The website is based on the source code. | Blog |